
🪶 RAG去重小助手SimHash算法:轻松解决文本相似度检测与查重难题
🎯 文章目标
本文面向爬虫开发者、数据分析师和RAG爱好者,旨在帮助大家:
理解SimHash算法的基本原理和优势
掌握基于SimHash的文本相似度检测实现方法
学会应用Python实现文本查重和相似内容识别
💡 小提示 本文包含完整的Python代码实现,复制即可运行!
📄 主题
本次主题:使用SimHash算法实现高效文本相似度检测
📚 通过本文你将收获
SimHash算法的工作原理与应用场景
文本相似度检测的完整Python实现方案
实用的文本查重技巧与优化方法
基于相似度百分比的智能判断策略
在搜索引擎、RAG系统与爬虫中的应用实践
🚁 前言
在信息爆炸的时代,如何快速识别相似文本、检测抄袭内容,已成为内容创作、学术研究和搜索引擎等领域的关键挑战。传统的逐字比对方法计算量大且效率低下,而基于哈希的局部敏感算法提供了一种优雅高效的解决方案。上一篇文章中,我们有讲到通过bert等嵌入模型通过对文本之间的向量进行计算并对比相似度进行召回,但是大家有没有发现会出现一个问题,如果两个文本片段极度相似,交集重合率较高,怎么办?本文将详细介绍SimHash算法,并通过Python实现一套完整的文本相似度检测算法,看完这篇文章我想你应该知道怎么办了。
✨ 你好,我是筱可,欢迎来到「筱可 AI 研习社」!
🚀 标签关键词:| AI 实战派开发者 | 技术成长陪伴者 | RAG 前沿探索者 | 文档处理先锋 |
🏞️ 一、SimHash算法原理与应用场景
SimHash是一种局部敏感哈希算法(Locality-Sensitive Hashing, LSH),由Google工程师Moses Charikar于2002年提出,主要用于大规模文本去重和相似度检测。与传统哈希算法不同,SimHash的核心特点是"相似的文本会产生相似的哈希值",这使它特别适合文本相似度检测场景。
🧠 1.1 SimHash的基本思想
传统哈希 vs 局部敏感哈希
传统哈希算法(如MD5、SHA-1)设计的核心目标是最小化碰撞,即完全不同的输入应产生尽可能不同的哈希值。这种设计具有"雪崩效应"——输入的微小变化会导致输出的巨大变化。
相比之下,SimHash作为局部敏感哈希的代表,其设计理念完全不同:
相似性保持:相似的输入应产生相似的哈希值
差异反映:输入的变化程度应与哈希值的变化程度相匹配
降维表示:将高维特征空间压缩为低维指纹,同时保留相似性信息
这一特性使SimHash特别适合"近似匹配"问题,如文本相似度检测、去重和内容聚类。
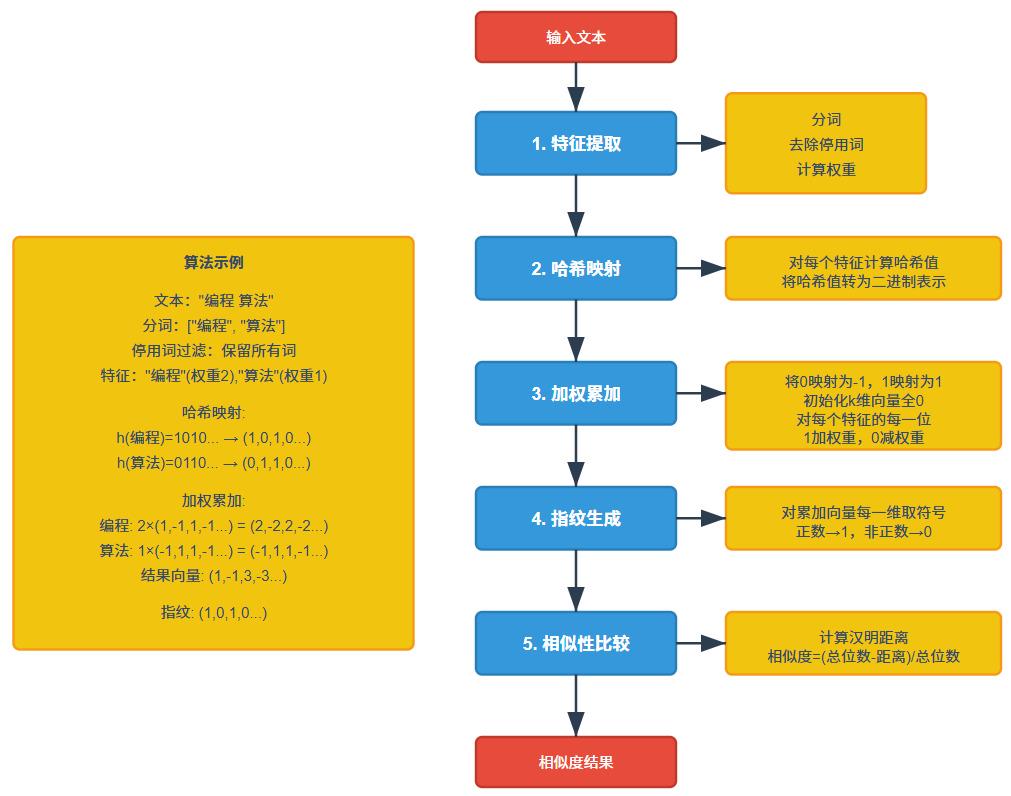
⚙️ 1.2 SimHash的工作流程
SimHash算法的基本步骤如下:
分词与特征提取:将文本切分为词语或特征单元 对于中文文本,通常使用分词工具(如jieba)进行分词 对于英文文本,可以简单按空格分词或使用更复杂的NLP技术,比如词干提取等 可选择性地过滤停用词,保留更有意义的特征
特征权重计算:为每个特征分配权重 最简单的方法是使用词频(TF)作为权重 权重决定了特征对最终指纹的影响程度
特征哈希:为每个特征计算哈希值 使用传统哈希函数(如MD5、SHA1)计算每个特征的哈希值 将哈希值转换为二进制序列,通常取前k位(k通常为64或128)
为了更好的阅读体验,来飞书看吧:
https://jiixflj4r94.feishu.cn/wiki/ZqRMwAlhaibYkUksiIKcHtsQnxz
Comments on "RAG去重小助手SimHash算法:轻松解决文本相似度检测与查重难题" :