
一、本篇背景
之前有同学遇到这个问题:本地部署ollama来跑deepseek,但是从后台看CPU利用率百分百而GPU(即显卡)利用率不足1%,且本地输出的deepseek输出较慢,一段对话一个字一个字蹦,没有完全利用好本地的显卡资源。本篇基于这个情况给出从CPU切换GPU的解决方案,同时对于需要本地使用Deepseek的同学给出Ollama的部署教程。(两篇教程合并到一篇写了)
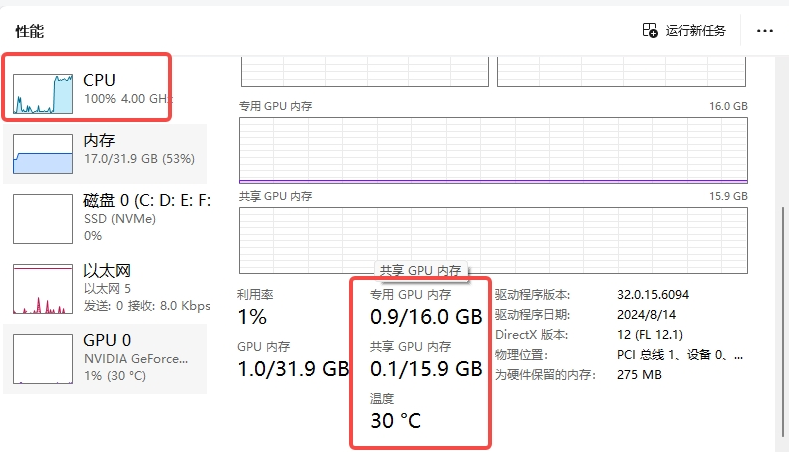
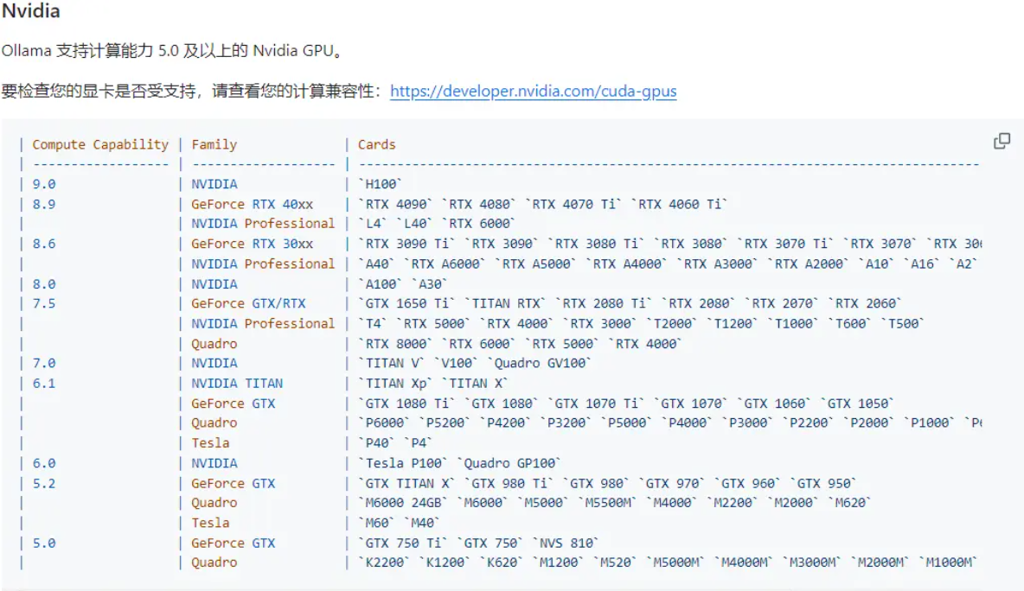
注意:本篇对于非程序员群体算进阶教程,过程不复杂,需要耐心照着教程走即可实现,但要求电脑为N卡配置,且内存够用能跑本地AI,教程参考前请先确认自己的电脑配置情况,优先确认自己的显卡是否在ollama支持的列表内(见下图),支持才能用GPU算力资源(本人电脑配置为AI电脑的基础配置:显卡NVIDIA 4060ti 16g+CPU intel i5-12400F+32g运存+2t固态内存用来放各类模型工具,跑SD/comfyUI/本地大模型8b及以下均流畅 )
指路:看ollama部署跳到第三步,需要切GPU跳第四步,新手可按顺序阅读。
二、相关问题解答
为什么要做本地部署?
一个是可以减少和绕过审核,保证完全的本地服务,不会泄密,同时也不用经历平台接口的内容已经输出一大半但又因为审核问题回吐的在线使用情况。
第二个是可以用本地部署+本地知识库的方式对自己本地的内容做AI化管理,构建自己的第二大脑,J人必备,且完全隐私可控,数据不会被用于平台模型训练。
本地部署的优缺点
好处:不联网
坏处:不联网
如何判断自己要不要用到本地部署?
需要:和AI提问一直被ban不合规;想要做本地知识库(日记/私人记录AI化/和过去的自己对话)
不需要:联网收集资料;需要满血版的使用体验;提问与交互都非常符合核心价值观
大部分时候联网使用各家APP开放的deepseek基本能够满足需求,本地部署其实除了特殊场景必要性不大,本篇教程仅作参考
三、如何使用ollama搭建本地模型
三步走:
下载ollama
下载模型到本地
对话框使用
第一步:官网下载ollama
地址:https://ollama.com/
功能:ollama只是一个软件,功能是平台有很多现在流行的本地模型,帮助你只需要一个指令就下载平台上最新的模型并使用它,不友好的点是:没有使用界面,所有操作指令都执行在cmd黑色的对话框中
1.操作:点击页面“Download”按钮。根据自己的操作系统选择下载版本,例如Windows系统,下载“OllamaSetup.exe”文件到本地盘(不要放C)
为了更好的阅读体验,来飞书看吧:
https://tue99hylfd.feishu.cn/docx/ElgYdULtooxDeYxnExmcJTmDnwh
Comments on "DeepseekR1本地部署超详细指南,解决 Ollama 卡顿,GPU 模式轻松上手" :