
大家好,我是嘟嘟,专注于ComfyUI赛道。
一、ACE++介紹
今天分享一个很令人兴奋的新工具,ACE++,这是阿里新开源的基于指令的图像创建和编辑通过上下文感知的内容填充。结合了FLUX.1-Fill-dev技术,仅需一张输入图像即可生成与角色一致的新图像,无需进行任何训练。
功能上体验下来有点类似以前那个in-Content lora,又有点像Redux,但是这个主要通过提示词来控制,符合未来发展方向。
简单来说,ACE++就像一个能听懂文字指令的"AI画师",你告诉它要画什么或者怎么修改图片,它就能按照你的要求生成或编辑图像。这个技术是基于目前最先进的"扩散模型"(可以理解为一种逐步添加细节的绘画方式)开发的。
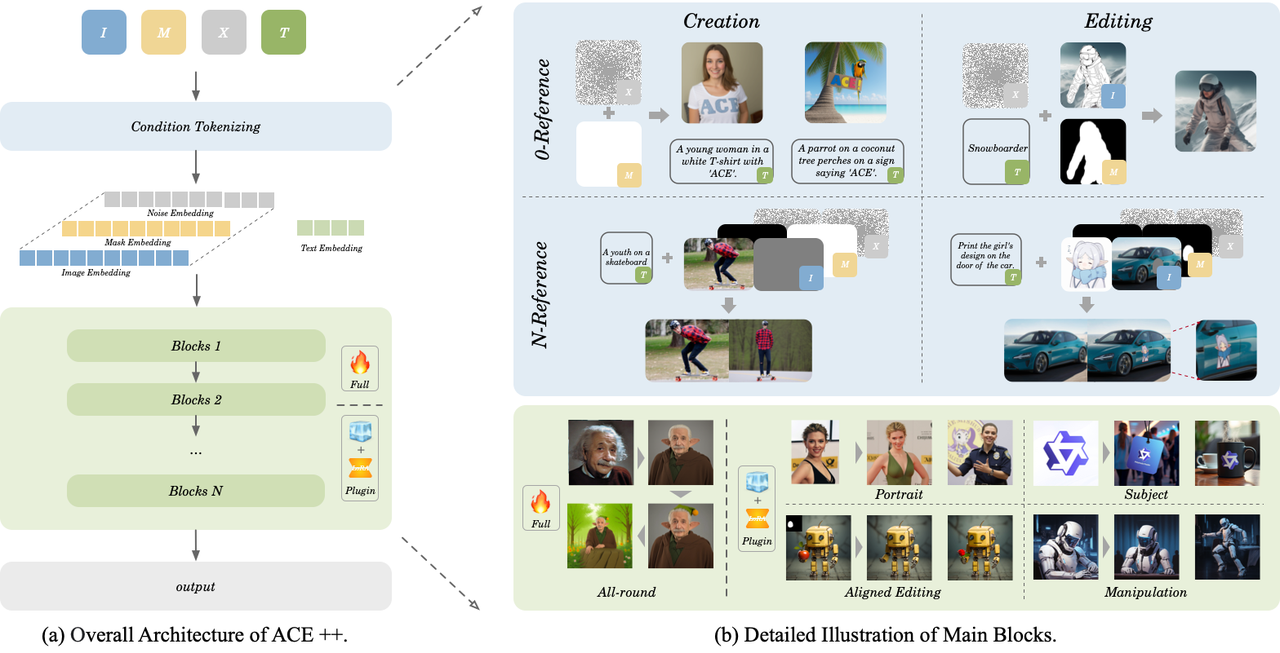
它最大的特点就是"全能"——不管是凭空生成新图片,还是给老照片修图(比如去掉路人、换个背景、换个脸),甚至处理多步骤的复杂编辑任务,都能通过统一的指令系统完成。这得益于他们改进了一个叫"长上下文条件单元"(LCU)的核心模块,让AI能同时处理更多类型的信息。
开发团队用了两步训练法来提升效率:
基础学习阶段:先用现成的绘画模型(比如专门修复图片的FLUX.1-Fill-dev)打基础,就像让AI先临摹大师作品掌握基本功。
专项提升阶段:然后让AI学习各种具体的图片处理技巧,比如图层编辑、参考图生成等,就像让画家学习不同画派的技法。
实际效果上,ACE++生成的图片不仅质量更高,而且对文字指令的理解更精准。比如你说"给照片里的天空加上彩虹",它不会随便加个彩虹,而是会考虑光线、角度等细节,让合成效果更自然。这比之前很多需要手动标注区域的修图工具智能得多。
项目主页:https://ali-vilab.github.io/ACE_plus_page/
Github:https://github.com/ali-vilab/ACE_plus
在线体验:https://www.modelscope.cn/studios/iic/ACE-Plus/summary
二、官方卖家秀


为了更好的阅读体验,来飞书看吧:
https://qnc80j2zlx.feishu.cn/docx/ZD73dAqiyoHks8xAY1yccgPjnIb
Comments on "[ComfyUI]阿里刚刚开源!ACE++秒杀LoRA:无需训练一键生成角色一致图像 | 支持在线体验" :