
🎬AI视频的"圣杯时刻"终于到来
还记得当年 PS 横空出世,彻底改变了图片编辑的游戏规则吗?现在,这一幕正在视频领域重演!
2025年12月1日,可灵AI发布了震撼业界的O1模型——全球首个统一多模态视频模型。
这意味着什么?
视频,终于可以像P图一样随意编辑了!
从AI视频技术诞生的那一刻起,所有创作者都在期待一个功能:
❌ 不满意视频里的服装?想换!
❌ 背景太单调?想改!
❌ 天气不对?想调!
❌ 想加个特效?想删个路人?
以前,这些需求要么需要专业的后期团队花费数小时甚至数天完成,要么就是——做不到。
但现在,可灵O1做到了。
不需要复杂的参数,不需要专业的后期软件,只需要动动嘴,用自然语言描述你的需求,AI就能帮你完成视频的精准编辑。
这不是PPT里的概念演示,不是实验室里的技术demo,而是已经全量上线、人人可用的产品级功能!
作为可灵AI的忠实粉丝,这两天对可灵O1进行了全方位测试。我设计了10个极限挑战场景,从换装、抠像、特效到风格转换,每一个都是实际创作中的高频需求和技术难点。
🔥 为什么说可灵O1是划时代的?
在正式测评前,先让我们理解一下可灵O1的技术突破点:
1️⃣ 全球首个统一多模态视频模型
传统AI视频工具:文字→视频(单向生成)
可灵O1:文字+图片+视频+主体 多模态混合输入,精准理解创作意图
2️⃣ MVL(Multi-modal Visual Language)理念
以自然语言为语义骨架
支持视频、图片、主体等多模态描述
操作直观,创作高效
3️⃣ 一站式创作引擎
不再需要在多个软件之间切换:
✅ 生成视频
✅ 编辑视频
✅ 添加特效
✅ 风格转换
✅ 绿幕抠像
全部在一个平台完成!
视频 O1 的五大亮点
全能引擎
将参考生视频、文生视频、首尾帧生视频、内容增删、风格重绘、镜头延展等多种任务统一到一个大一统视频模型中,避免在多个工具间来回切换 。
支持从灵感到生成、从生成到修改的一站式完整创作流程 。
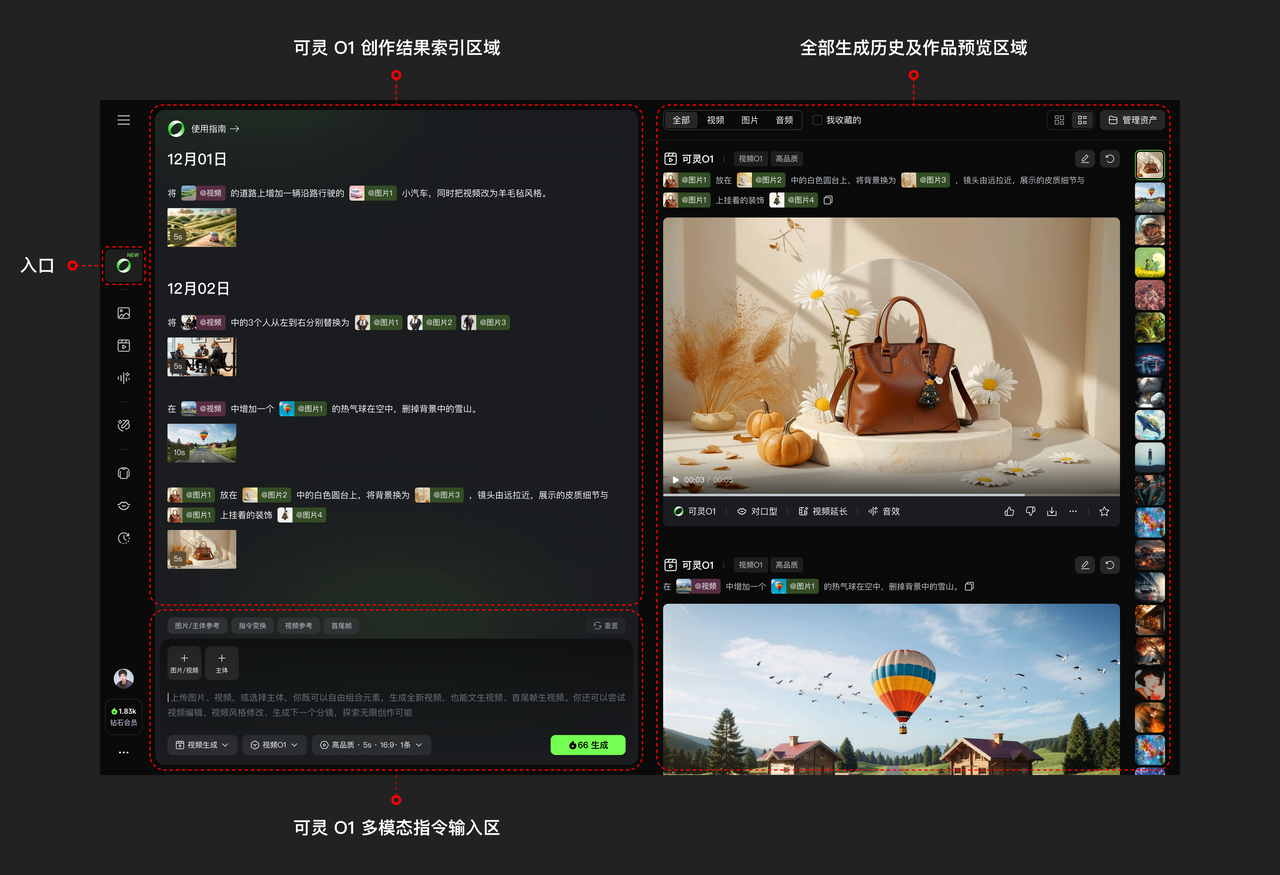
全能指令
支持文字、图片、视频、主体等多模态作为“指令”,模型能综合理解这些输入并精准生成视频细节 。
为了更好的阅读体验,来飞书看吧:
https://metafengai.feishu.cn/wiki/SNQCwF2ZtiatQGk7c1dc35WqnZf
Comments on "可灵视频O1模型:视频界的Photoshop来了!动动嘴就能P视频" :