
前言
之前在一个AI编程实战群我看到有不少圈友尝试让AI写个程序跑个爬虫总是遇到各种报错问题。详细查看了下,大部分都是没找到定位到元素的问题。
而我作为当时参与的志愿者,就顺带做了个分享,也就是这篇稿子。
我认为用好AI,是可以边学习Python语法边去实践爬虫和RPA的。这篇文章不会提及Python相关安装问题,默认已安装。
需求分析
首先,建议使用Claude 或 GPT4/4o ,目前提问代码相关的问题,我个人觉得 Claude 效果是最好的。
接下来以爬虫B站视频标题来举例说明。
我们想要去爬一个网站数据,首先要了解这个网站,B站可以不用登录简单浏览。
如果我们想爬取B站AI相关视频前100条内容,那要如何做呢?
我们把PY程序想象为人就行了,我们自己看100数据是不是一直刷?B站的话,还需要翻页。
人:刷B站,点击翻页。PY程序:看代码,点击翻页。
其实是一样的,只是PY程序看的是代码而已,它看的速度也比我们快多了。
实战演示
接下来我以无Python编程基础的方式演示一下如何爬取100条B站标题数据:
第一步 打开B站搜索AI
第二步 打开开发者模式
右键检查或打开F12,找到最左侧的这个选择元素的按钮(元素检查器),点击一下。然后鼠标移动到第一个视频的标题部分会有绿色背景显示,点击一下。这样我们就看到了相关的源码。有用过八爪鱼或后裔采集器的话,会感觉到这个步骤是类似的。所以也是说,无论用RPA/采集器其实底层原理都是一样的,编写selenium的代码可以理解为就是那个底层技术。
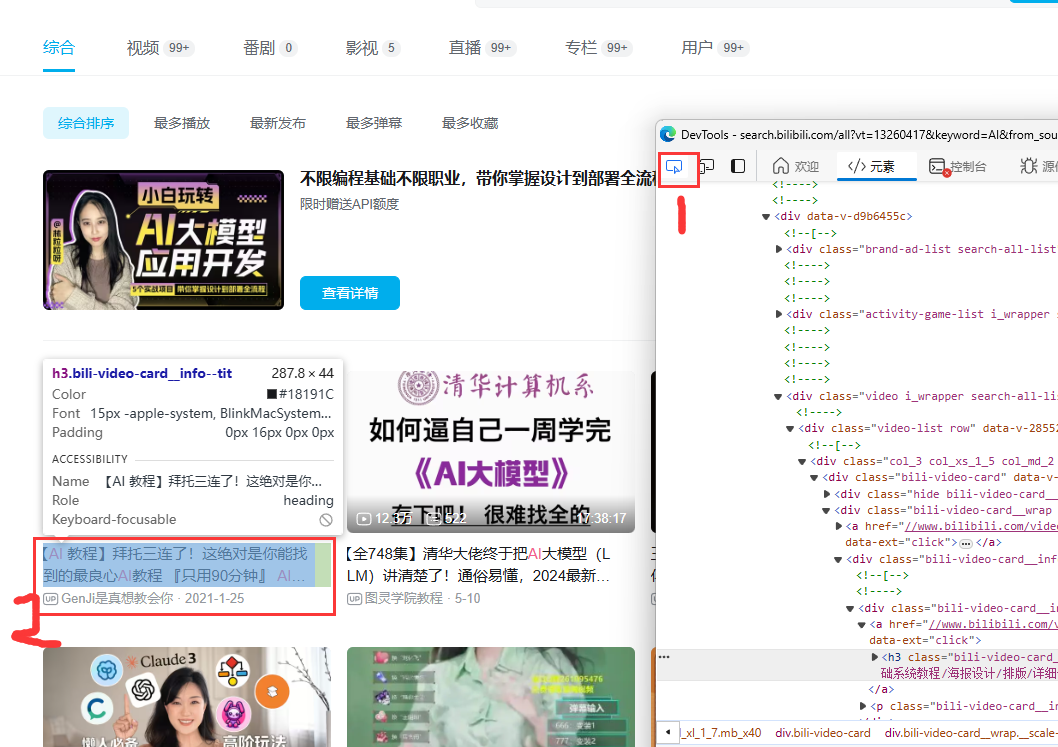
第三步 复制源码
为了更好的阅读体验,来飞书看吧:
https://ktnwm6ohjn.feishu.cn/docx/GM3wdFmtBoL8MfxN9aqcLkv4nob
Comments on "零基础如何用好AI来爬取数据" :