
主要知识点: 爬虫,firecrawl,RSS 信息订阅,飞书 等等
这个工作流是参考秋芝的工作流的骨架,进一步升级的,尤其针对去重逻辑和时区不一致问题。
你将收获:一整套低风险、高稳定、易扩展的资讯采集打法——优先 RSS/API,其次 Firecrawl 半托管抓取,最后才用 HTML 解析。还会学会用 Split In Batches + Wait 做限流、用 去重 + 持久化 做“冷静大脑”,并最终亲手搭出可用的热点资讯工作流。
一)工作流地图(先给全景,再走细节)
1、PPRR 循环(Perceive→Plan→Run→Reflect)
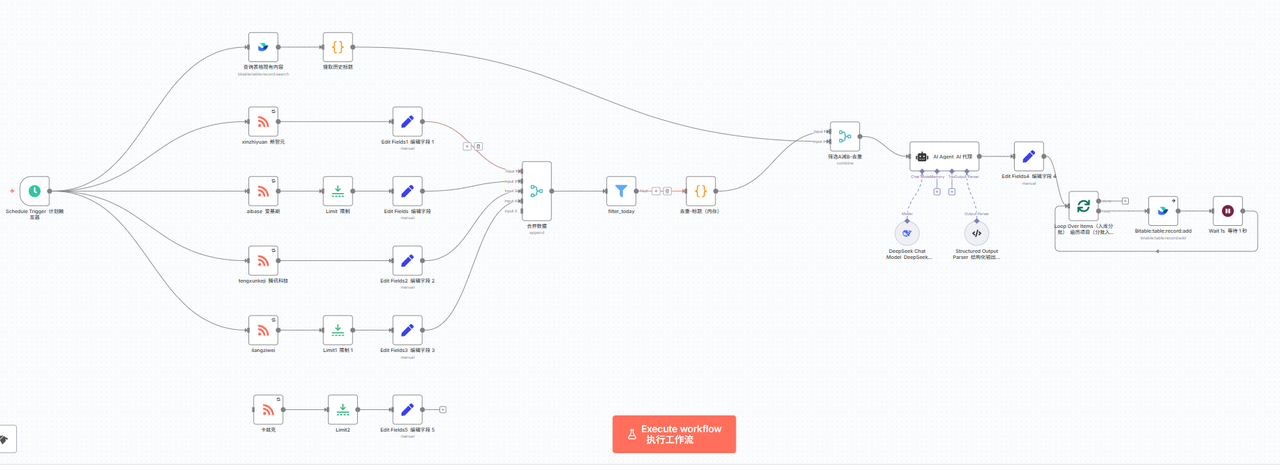
1)感知:Schedule Trigger / RSS / Webhook
2)规划:Set / Code 统一字段、决定处理策略
3)执行:Split In Batches + Wait 限速批处理、HTTP / HTML / Firecrawl 抓正文
4)回顾:去重、落库(Feishu Bitable / Notion)、告警与监控(Error Trigger)
2、实战成品(今日目标)
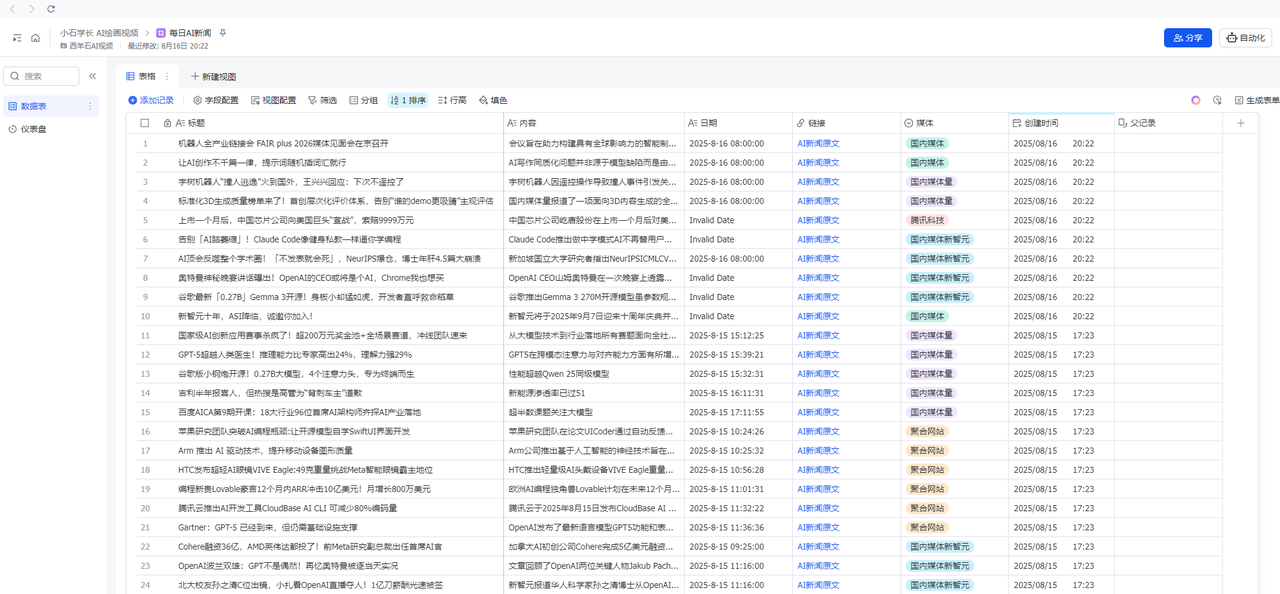
1)每日定时聚合多路 RSS → 清洗/去重 →(可选)Firecrawl 抓正文 →(可选)LLM 摘要标准化 → 写入飞书多维表 Bitable / Notion
二)预备知识与环境
1、你需要准备
为了更好的阅读体验,来飞书看吧:
https://arhw4sutfj.feishu.cn/docx/KWrHdTMuGo4JW7xY6dRcgK1UnZg
Comments on "五、 进阶|n8n 爬虫技巧 & 热点资讯自动收集实战" :