
本人是一名后端程序员,工作中使用AI编程工具是:Trae,主要是因为它能够免费的使用claude系列模型,这个系列的模型在代码方面非常给力。下面分享的是自己帮朋友做的一个小工具,总共耗时2小时。
1. 初始需求与灵感
大家好,我是时光。下面给大家分享一下我用AI辅助制作长图文字识别工具的过程,包含实现思路和复盘思考。
3月19日晚上快12点了,我刚刚完成其他破局行动的打卡,无意间看到了洋哥发的帖子,号召大家用AI编程实现一些工具。看到这个帖子,我却有些迷茫——到底应该做什么工具呢?
就在我思考的时候,一位朋友向我提出了一个实际需求:
"你能不能帮我实现一个图片裁剪工具,我可以提供一个长图,希望能够设置高度,按照高度裁剪。"
这个具体的需求立刻让我找到了尝试的机会。有明确问题比漫无目的地探索要高效得多。
2. 第一阶段:图片裁剪工具的实现
考虑到只是个人使用,我决定采用最简单高效的方式实现——纯前端HTML页面。这种方式无需安装任何软件,只要有浏览器就能打开使用。
我打开Trae,输入了详细的提示词:
"我希望用html实现一个图片切割工具,可以上传图片,按照高度裁剪,网页支持预览功能,可以导出裁剪后的图片,以压缩包的形式下载"
AI直接生成了功能完整的HTML界面,包含了所有必要功能,测试后效果良好。这种简单的前端任务正是AI的强项,只需要清晰描述需求,AI就能快速生成可用的代码。
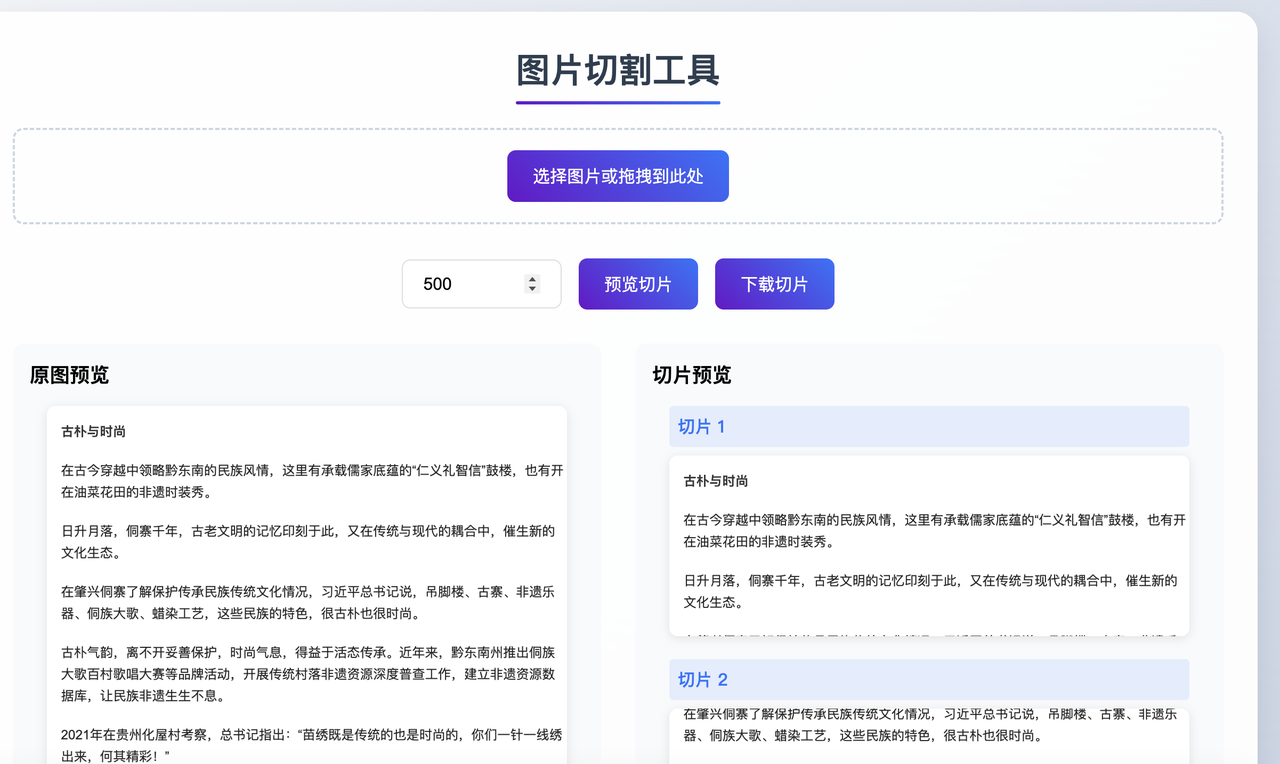
此时html、css、js都在一个文件是为了方便使用者方便。
3. 需求升级:添加文字识别功能
完成基础功能后,我朋友提出了更高级的需求——能否实现文字提取?
她解释道,她原本是希望把微信群聊天记录整理出来,但因为长图限制,需要先切割再逐一提取文字,过程繁琐。
我立即意识到这是个典型的OCR(光学字符识别)应用场景。OCR是一种能够将图片中的文字转换成可编辑文本的技术,现在很多手机扫描文档的功能就是用的这项技术。
为了更好的阅读体验,来飞书看吧:
https://cftfzv3x1g.feishu.cn/wiki/Z8sBwSJBjix2sgkiHBgcS0qVnqb
Comments on "AI编程实践:长图文字识别工具的开发之旅" :