
〇、写在前面
这次前后花了两天半,除了吃喝基本没做其它事情,不停地捣鼓ChatGPT,让它帮我写了一段Python代码,成功爬取到自己想要的数据。
先简单介绍一下自己的Python 水平,懂一点基础元素和 For、IF等常见语句,进阶的基本不懂,自己写基本什么都写不出来那种小白水平。
因此,基于本次实现过程做一个复盘和分享,相信也有情况跟我类似的朋友有此需求,希望能对大家有所启发。
读完这篇文章,至少可以让你学会以下几个技能:
如何让ChatGPT帮你写爬虫
如何在网页中定位&提取Class的标签和值
如何让ChatGPT帮你合并多个表头相同的Excel文件
一、为什么让ChatGPT帮忙写爬虫?
因为个人参与了web3的投资,最近基于谷歌表格,做了一个仓位管理的工具(以下是部分截图)

其中的标的现价,是结合谷歌表格的Importhtml函数自动获取的,代币的数据源https://coinmarketcap.com/网站(下文简称CMC网站),数量9000多个。
为了充分提取这些数据,于是我想到了爬虫,一开始没想着写爬虫的,毕竟市面上有现成的工具,比如某羿采集器,但是研究了大半天,取出来的数据像下图这样,很大一部分都有缺失(多半是我自己的问题)。
之前就得知ChatGPT可以帮忙写代码,我就决定调整思路,尝试“调教”一下。
二、如何调教ChatGPT并实现抓取?
整个实现过程并不是想象中的一帆风顺,远比想象复杂,经过了很多次失败和调试,为了提供更多有效信息,我会把提问过程进行简化,并把整理后的对话文档放到2.2的最后。
2.1 关键信息
整理一下对话的关键信息:
对话模型:GPT-4
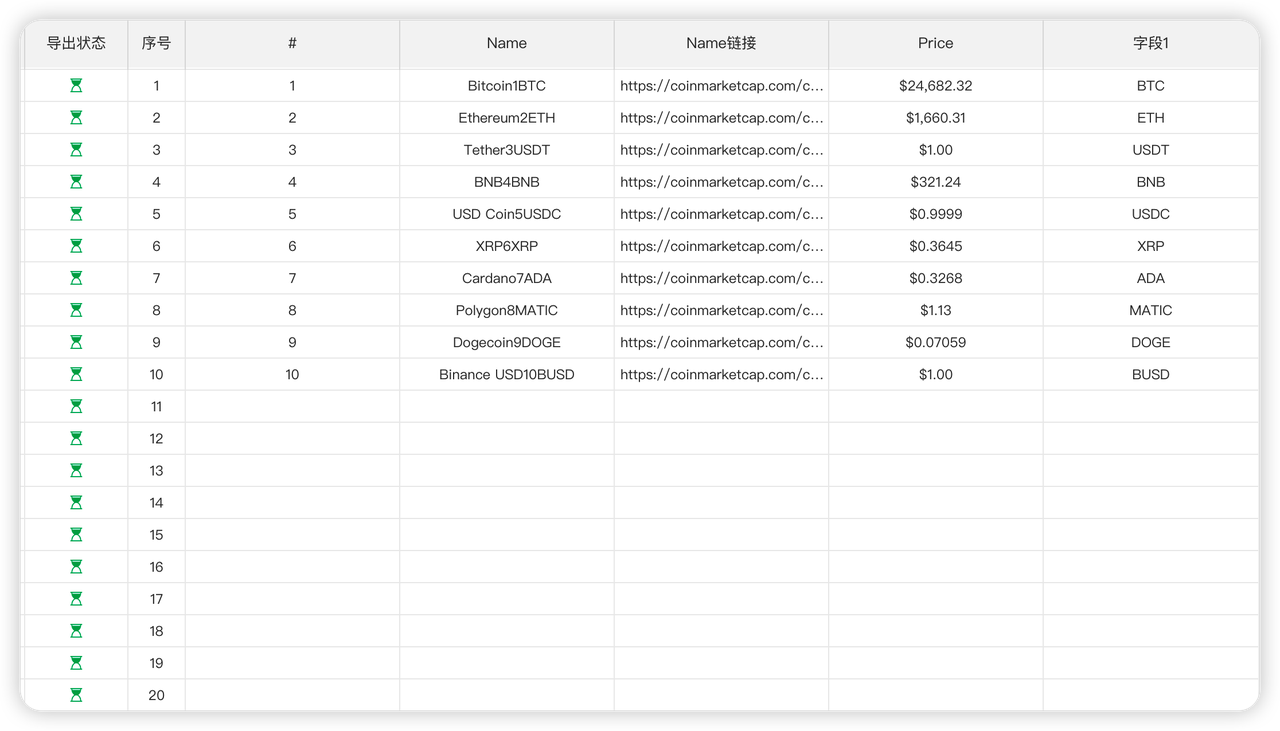
个人需求:采集https://coinmarketcap.com/网站全部的代币名称、简称和二级网址,并保存至Excel文件
代码运行环境:Pycharm(另外安装了Anaconda)
2.2 聊天内容
接下来直接进入主题,因为之前我聊的那个版本内容太多太杂(简称V1版),我就重新聊了一次(简称V2版),以下是我重新聊的V2版本中我发送的主要内容(比V1版本更简洁,GTP-4回复内容见2.2附件)
你是一名专业Python 的程序员,可以帮我抓取一个网站的数据吗
我会发给你一个网址,再告诉你需要爬取的字段信息,你给我代码
网址:https://coinmarketcap.com/ ,需要提取的字段:代币名称、代币简称和代币名称的链接,在该网页的第1个代币名称是Bitcoin,其代币简称是BTC;第2个代币名称是Ethereum,其代币简称是ETH;第3个代币名称是Tether,其代币简称是USDT;然后在用户名为qingche的MAC电脑桌面新建一个文件名为new的excel文件(如果有同名的文件先删除),把提取的数据存进去
我已经安装了requests, beautifulsoup4和openpyxl库,出现了以下错误代码,先帮我分析再更新代码(错误代码略)
我发现有两个问题,1、只获取了后面90个代币名称,前面10个没有获取到,2、代币简称没有任何数据,先帮我分析可能的原因和解决方案,并更新代码
为什么执行完没有任何提示
为了更好的阅读体验,来飞书看吧:
https://c5b5kd78s1.feishu.cn/docx/W9bkdxL8Iouy7PxPFBMcSP9qnLh
Comments on "Python小白如何调教ChatGPT写爬虫" :