
大家好,我是亮仔
简介
此前有个selenium的爬虫案例,但是环境配置是一个麻烦的问题
总有人说,只要执行力强,没有办不到的,但是我们还是需要考虑性价比的,毕竟程序员那些插件,什么chrom_driver啥的真是麻烦,还要匹配版本,还要安装chrom,有没有办法,既不用写什么代码,也不用安装什么chrom,只需要简简单单的让gpt给我写一个代码,我直接拿来用呢
方法当然是有的,我今天就是来拯救你的【不过python环境还是必须的】 那么我们,action
声明:本案例最终可以实现爬取几乎大部分平台,如下案例只是作为参考,换了网站只需要更换提示词和文件,而非此前生财案例中的爬取部分平台/本地文件,但也仅作参考使用,请勿用于非法用途
步骤
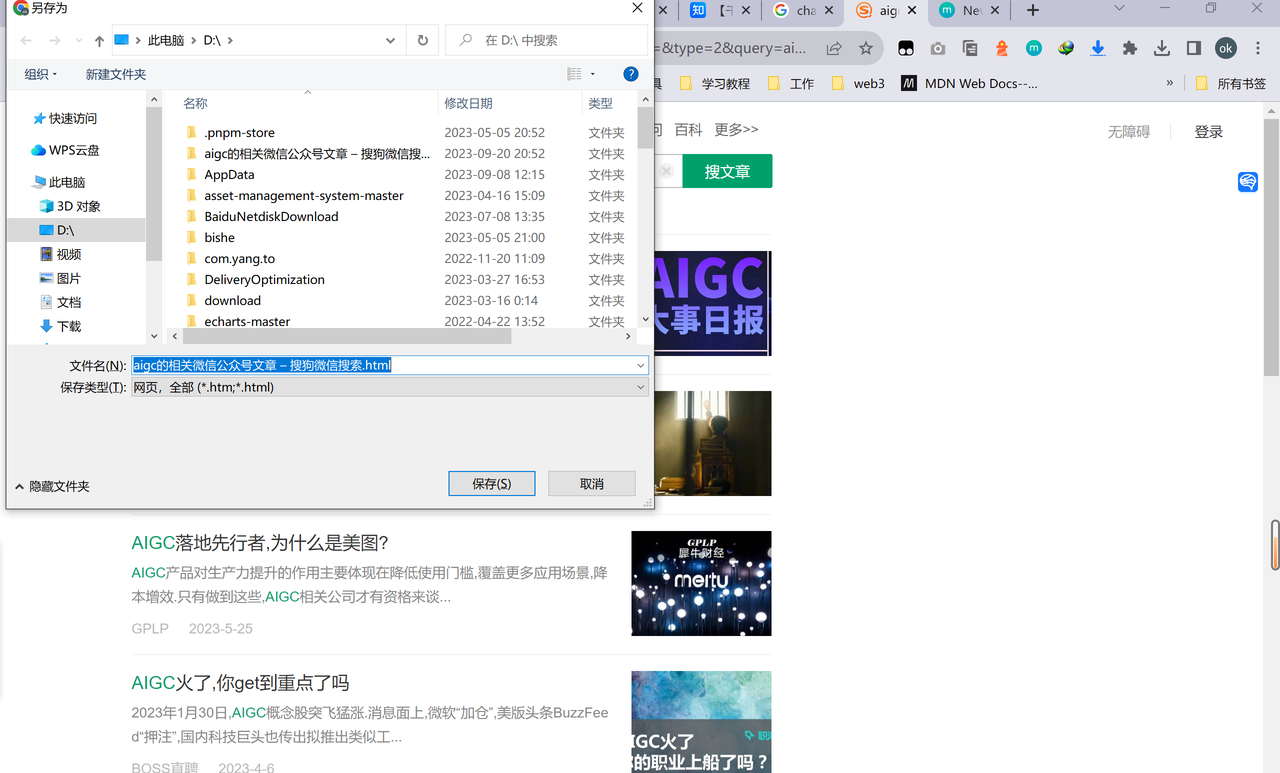
1,下载目标页的内容
这一步看起来不聪明,主要是为了读取结构,毕竟我们小白并不懂什么网页结构,也听不懂专业术语,我就给你 我的目标网页,剩下的我就不管了
ctrl+s就可以直接保存该网页文件到本地,这里最好就保存到固定本地某个盘(c/d),方便后面上传
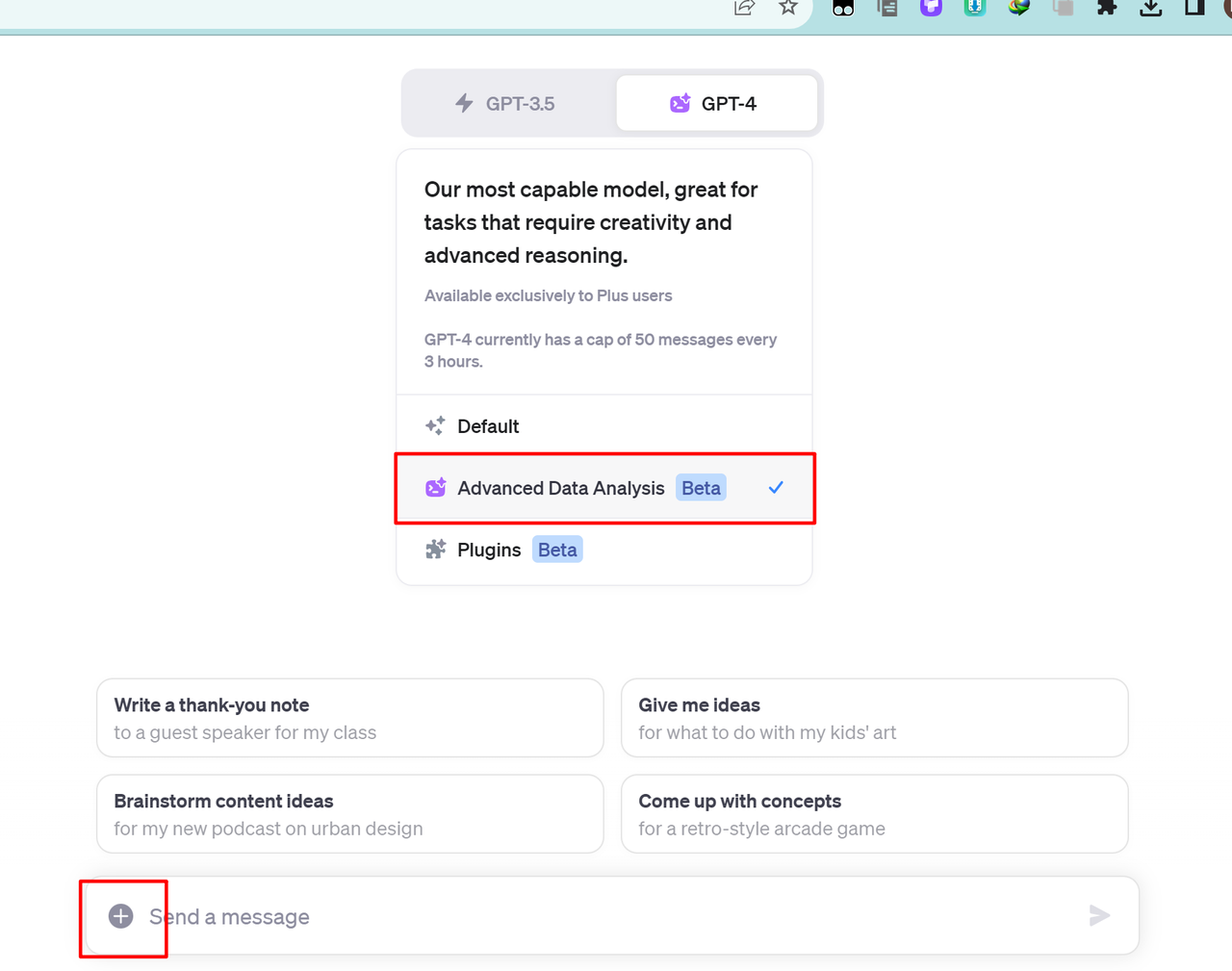
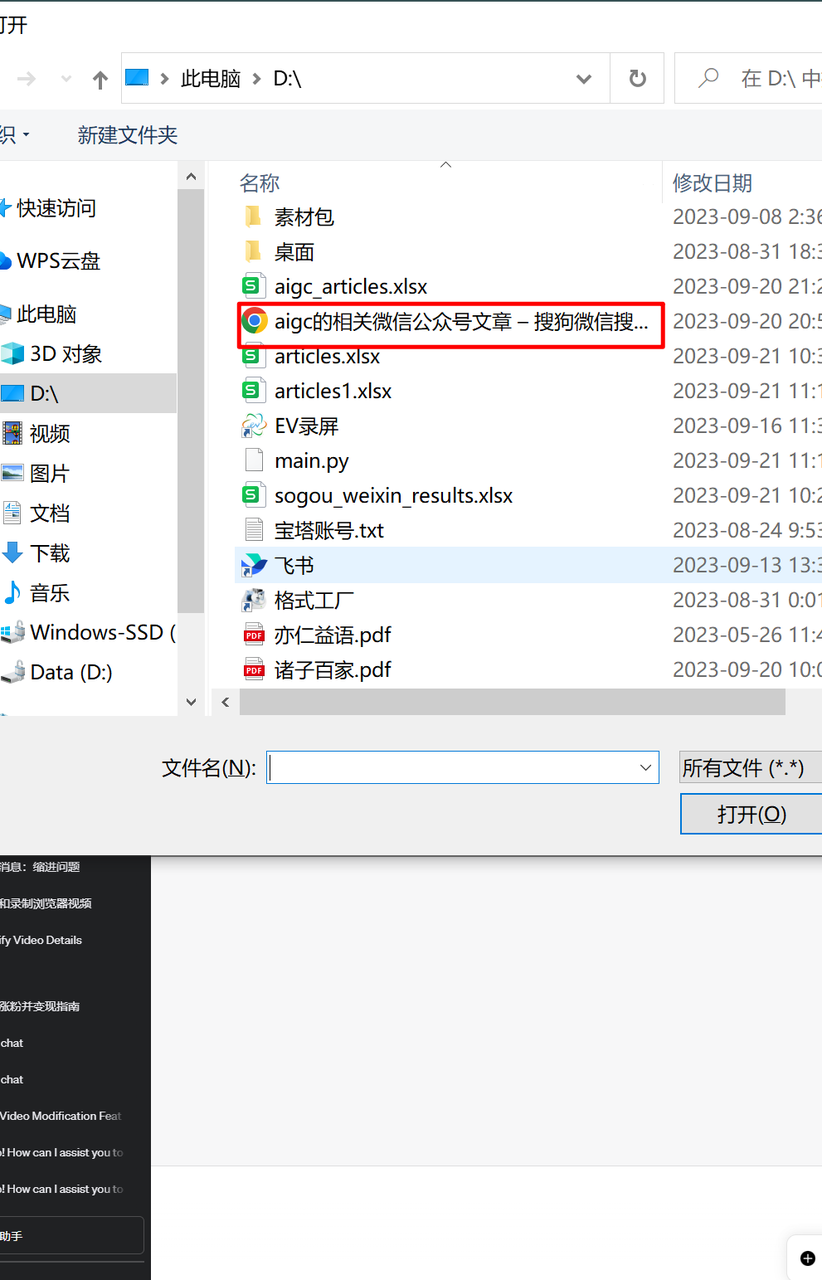
2,上传对应的网页文件并给gpt喂提示词
①上传文件
记得是html
为了更好的阅读体验,来飞书看吧:
https://bc8fd5oefm.feishu.cn/docx/F8VxdpYUxovdgkxVeTpcPZLXn4P
Comments on "使用gpt,小白不用一行代码就可以爬虫 " :