
温馨提示:7000字长文,请准备好至少半小时以上完整时间阅读,并且非常建议您跟着教程操作。
前几天,我朋友跟我吐槽:
“每天翻 Boss 某聘翻到眼花,岗位又多又杂,真想一键导出来慢慢筛……可惜我不懂代码。”
我直接笑出声:
“都2025年了,连我妈都知道用 AI 了,你还在手动点?”
然后我带他从 0 到 1,用了不到一个小时,他这个完全不懂编程的人,就把所有招聘信息爬成了一张 Excel 表格。
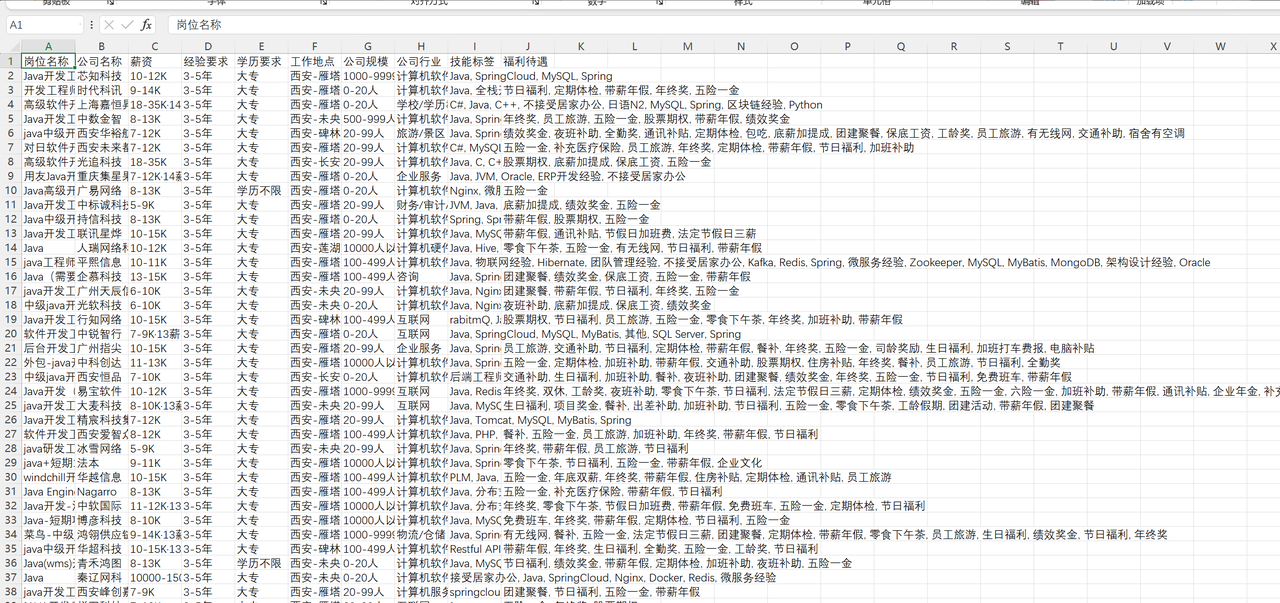
爬取文件如下:
我就想,随着AI时代的到来,真的就是把很多东西降低了门槛,让普通人也可以触碰到以前遥不可及的领域.
所以就有了今天这篇文章。
AI爬虫核心就这五步,全程不需要你写一行代码:
1、明确爬取的目标网站以及自己想爬取的数据。 2、通过浏览器控制台,找到对应内容的数据。 3、根据数据所在的位置找到对应的数据信息。 4、把数据信息发送给AI。 5、运行AI代码,得到想要的数据。
下面我将一步一步手把手带你,爬取你想要得到的数据。
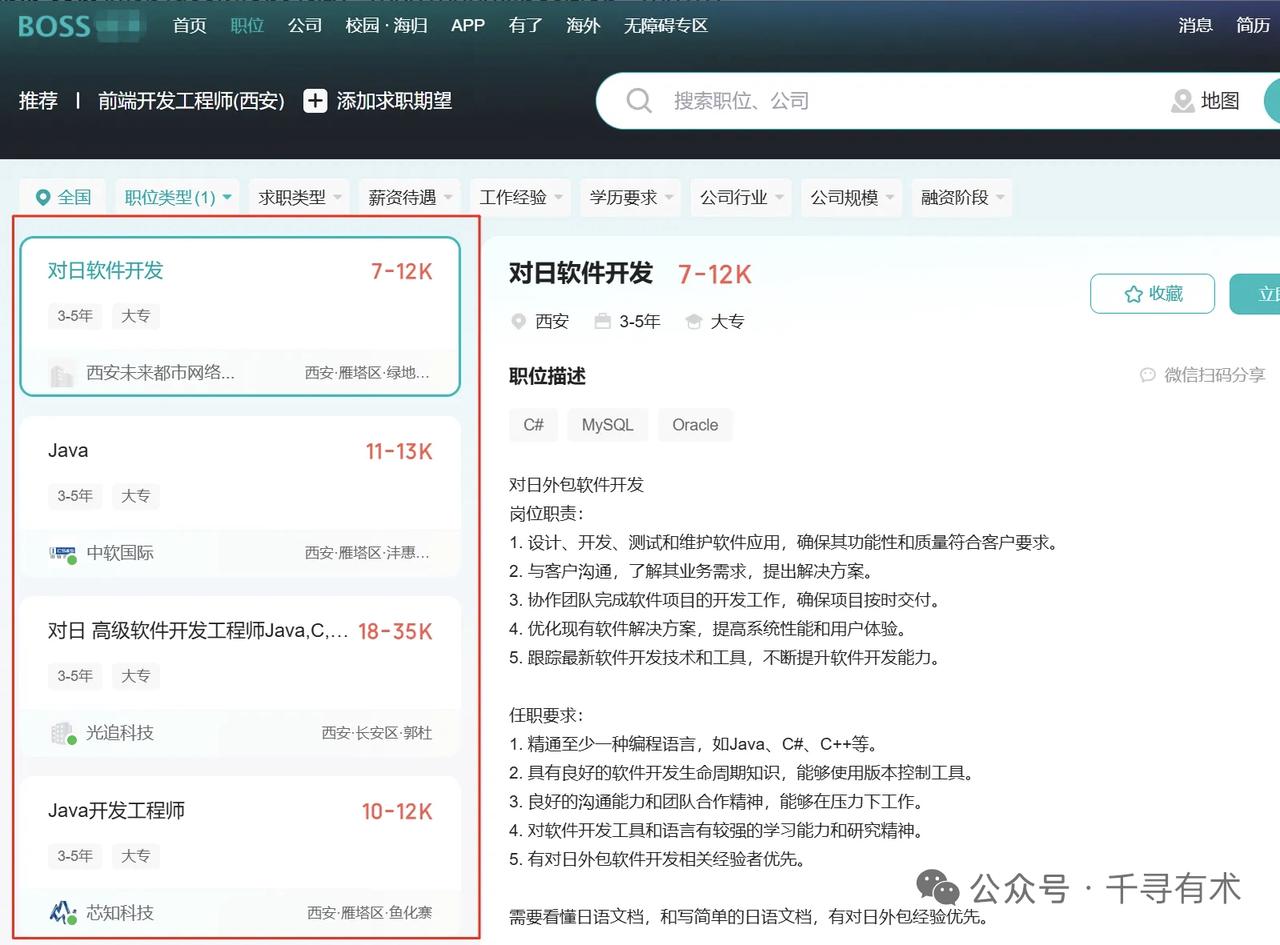
第一步:确定目标网站
我们以boss某聘网站为例,显然,左边的列表是咱们要爬取的信息。
为了更好的阅读体验,来飞书看吧:
https://a0u2vshvubw.feishu.cn/wiki/V6KAwSTpliEvo5k4y2qcILHon6e
Comments on "AI爬虫,不会代码的小白,也能硬爬你要的数据" :